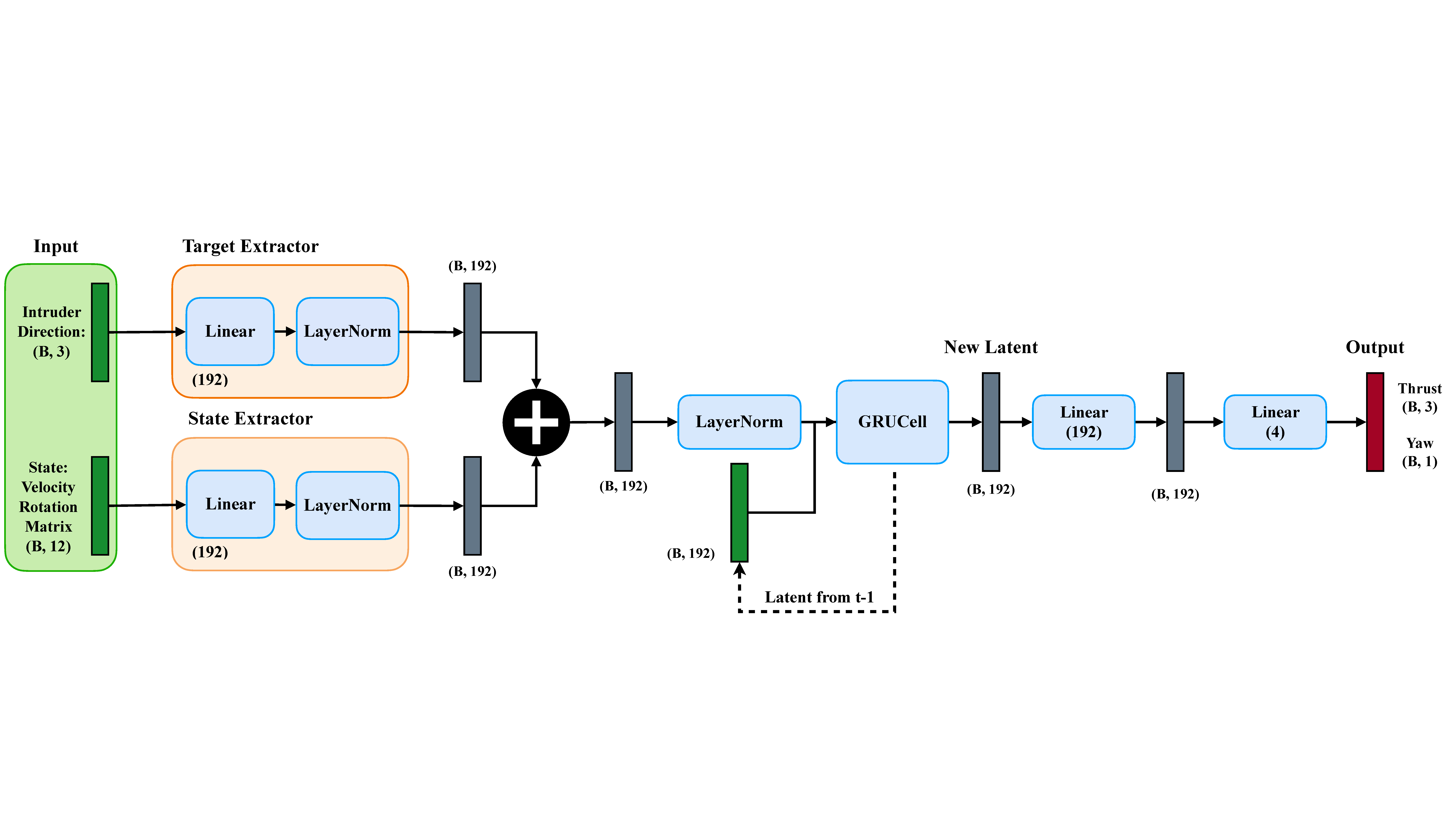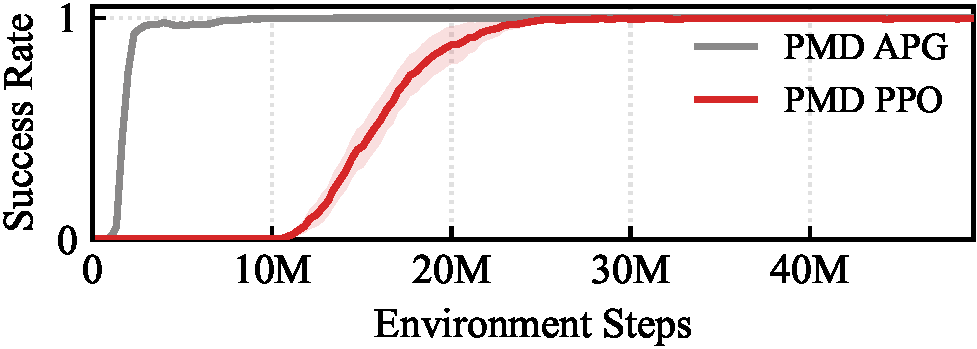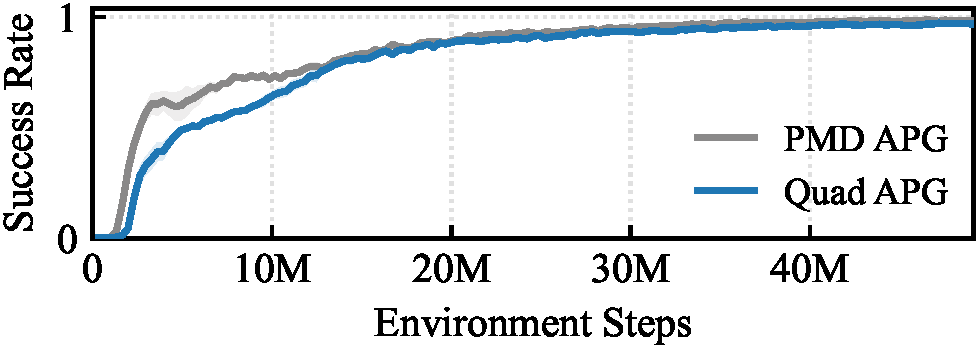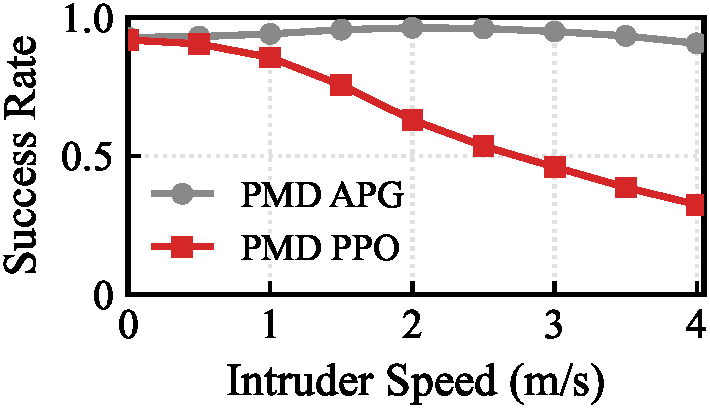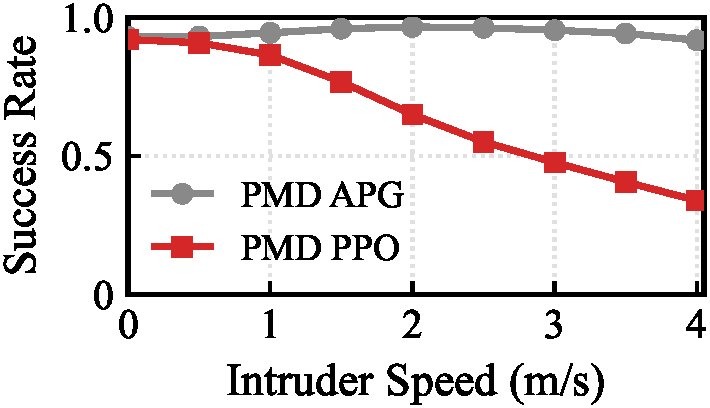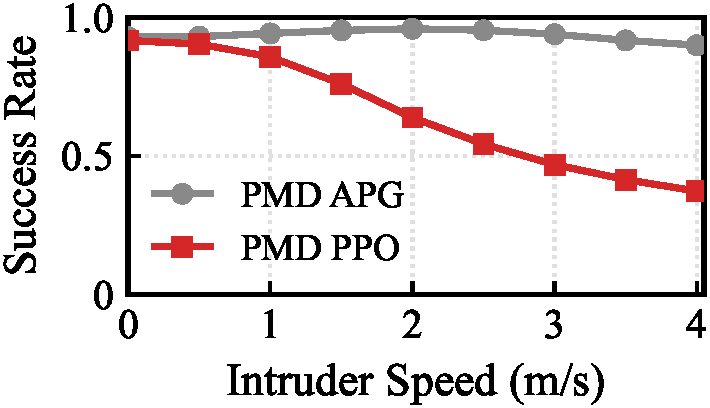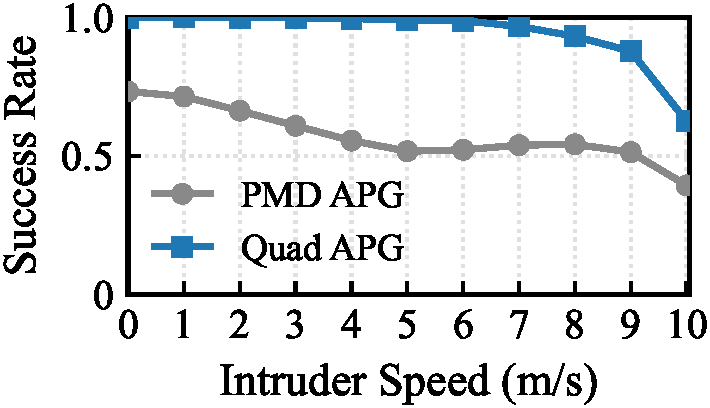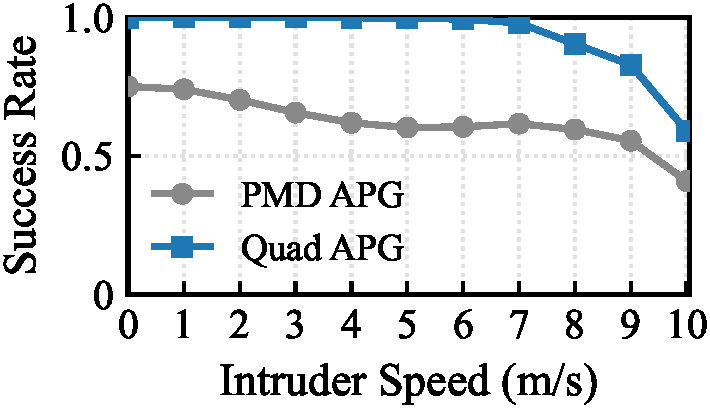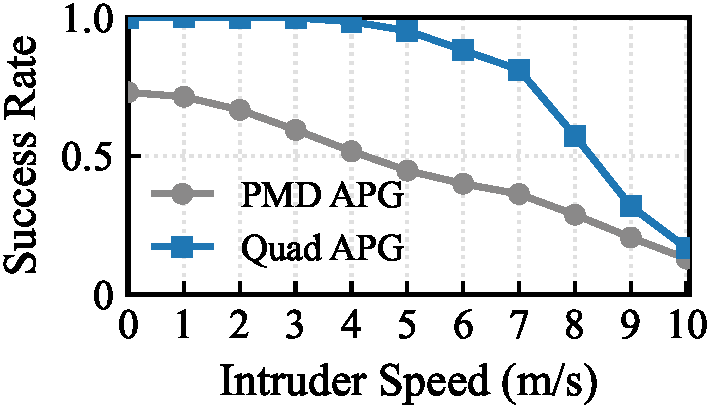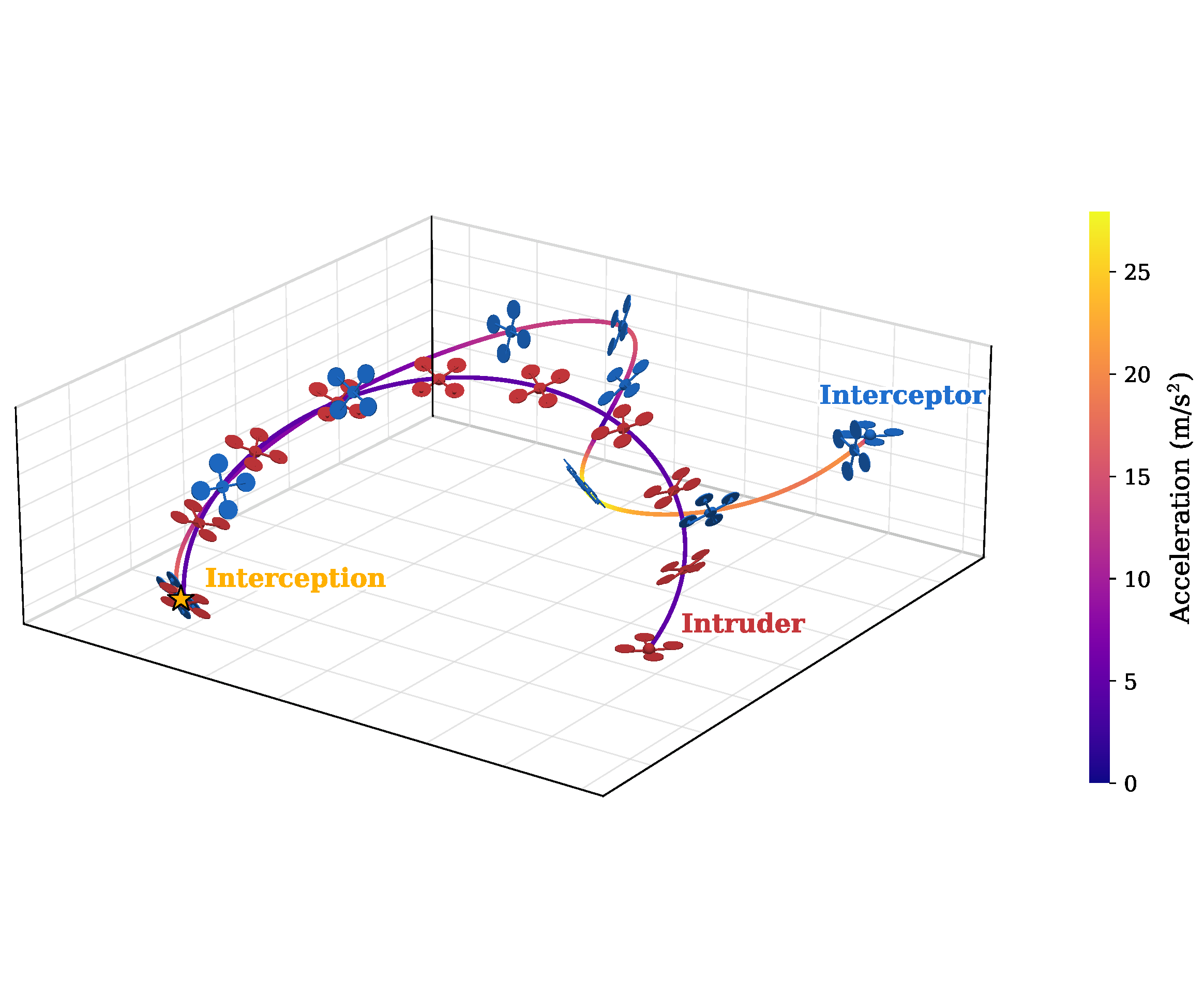
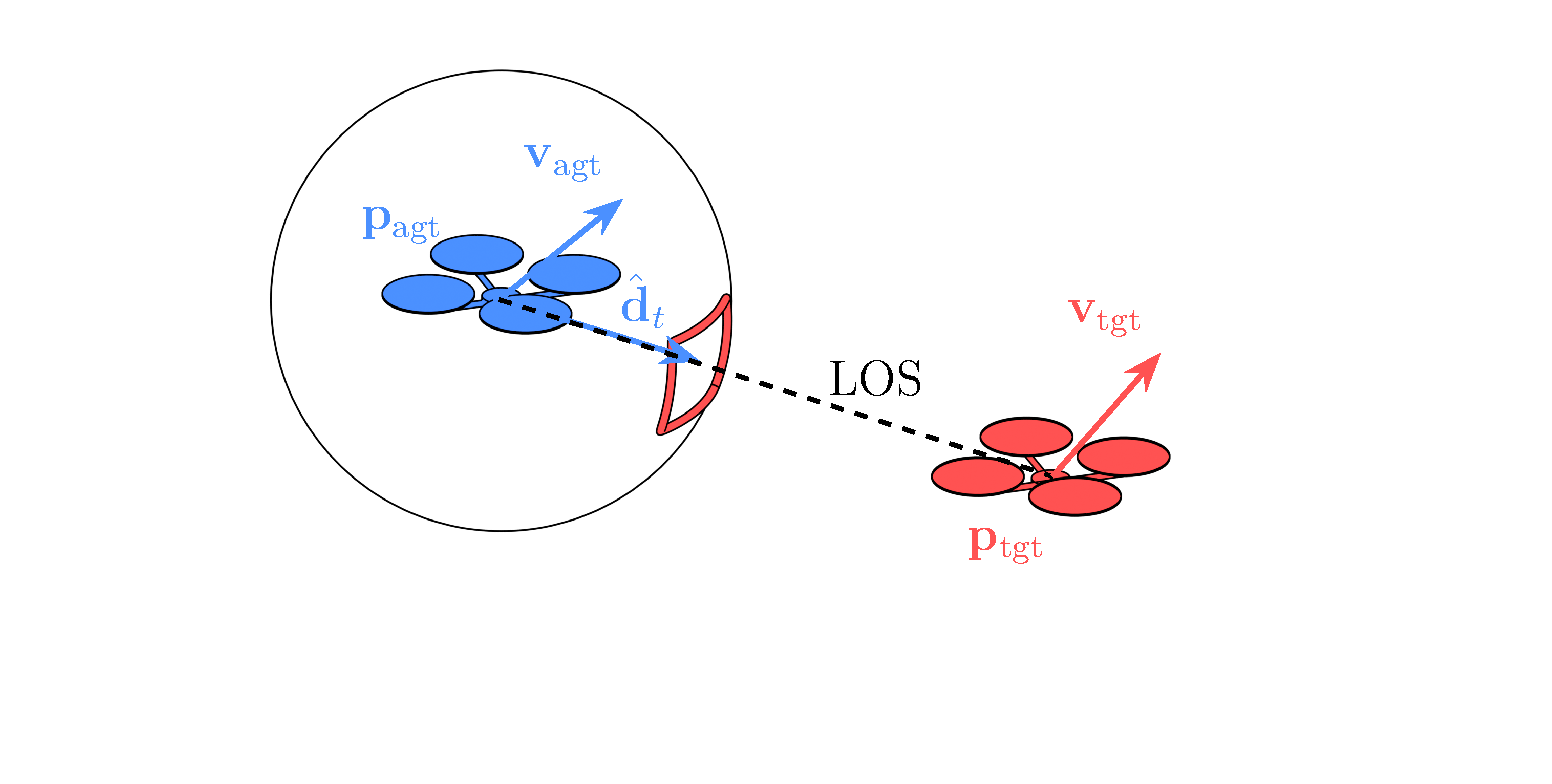
Inspired by classical homing guidance, the training objective decomposes parallel navigation into two key parameters:
- Line-of-Sight Alignment: Penalizes the angular drift between relative position and relative velocity, forcing the relative velocity to point along the line-of-sight.
- Closing Velocity: Maximizes the closing speed along the line-of-sight vector, driving the agent to aggressively close the gap rather than simply shadowing the target.
Privileged Information: Intruder state details are privileged and used only in the loss function
during training, never at inference.